

Space Infrastructure for Safe Computation: Talk by Filip and Toufic at EthCC

Last week, CoFounder Filip Rezabek and Applied cryptographer Toufic Batrice from the SpaceComputer team attended the Ethereum Community Conference (EthCC) in Cannes, France.

They gave a talk 'Stars to Bits: Space Infrastructure for Safe Computation' which focused on the opportunity, challenges, and applications of building in Low Earth Orbit (LEO).
Watch the full talk on YouTube:
So I believe some of you might have already heard in the recent weeks, months, about the hype regarding space data centers. And as we can see, more and more, it's not only becoming a hype, but it's actually becoming a reality. We have many companies working on it.
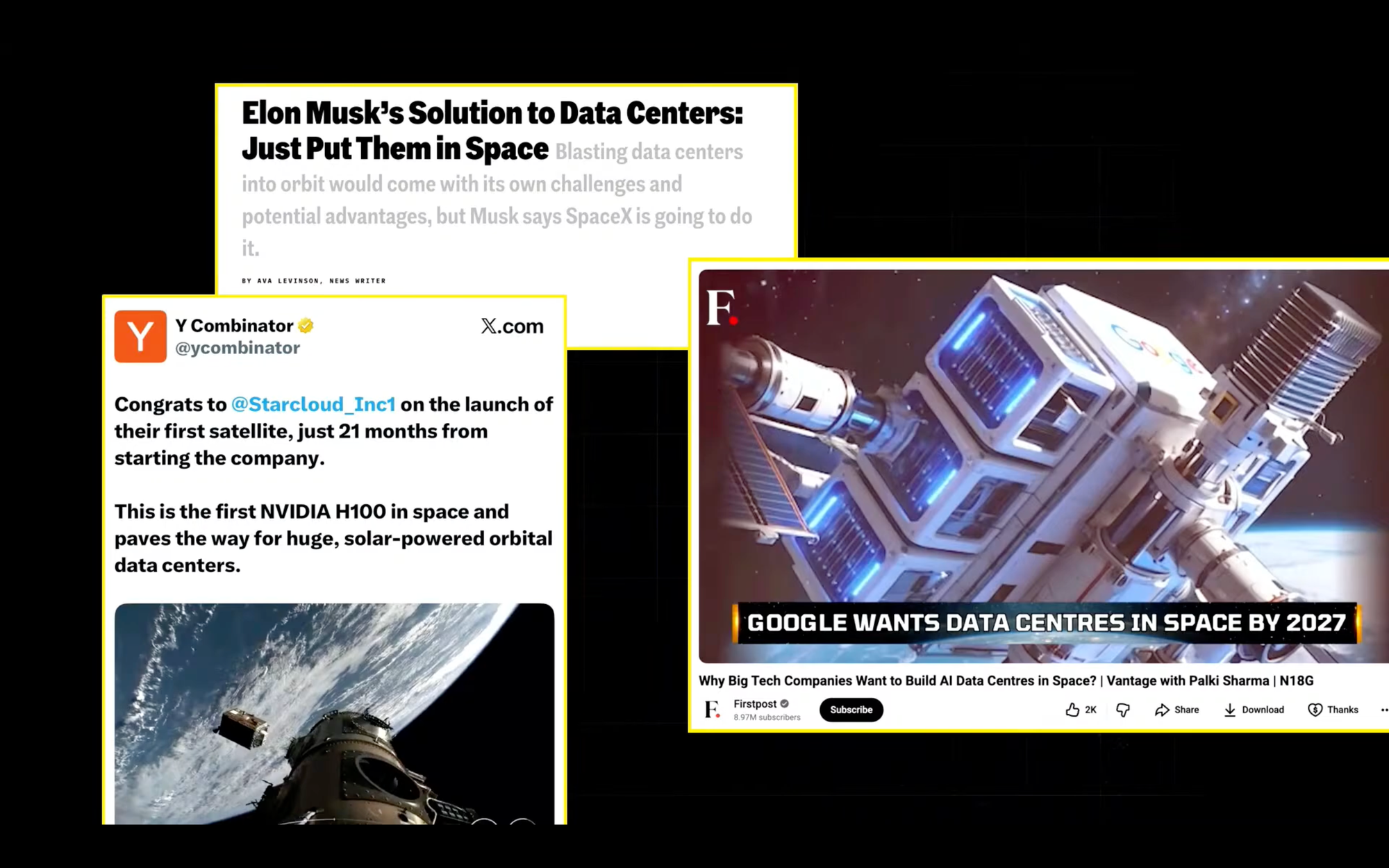
Google and SpaceX are already looking into the solutions. One to note is also a recent startup from Y Combinator called Starcloud that just a few days ago raised a Series A of $170 million to make efficiency of space data centers comparable to the ones on Earth.
So while we see more compute will be shifting to space, what does it mean for the startups building in the space?
Space is open for business more than ever before. Most of the industry unlock and capabilities is, to be fair, due to SpaceX. They are leading launch the industry with the most efficient and cost effective vehicles that make sending any type of gear to space is becoming cheaper year over year.
When the space industry started taking off, launch costs for sending a kilogram to space was in the order of tens of thousands of dollars. Now with Falcon 9, it's in the order of thousands of dollars. And with Starship, which should be available in the next years, we are talking about hundreds or even tens of dollars per kilogram, which unlocks many new use cases that were not really thought of before.
What does this mean for SpaceComputer?
We envision there will be a large need for security in this context, because space itself plays an important role in many activities regarding communication and other applications, depending on the customer.
We focus on providing:
- Communication with respect to edge computing and security.
- Execution of any type of sensitive workload on a satellite in space, like AI inference.
- Key storage and providing secure capabilities for your systems in LEO
- Ensuring and verifying your workloads are truly running in space
- Space-sensitive applications that will be fully developed for both space-native Earth-to-orbit services.
The question is, what is the state of space as of now?
We see that definitely there is a huge potential for the next 10 years, with respect to Starlink being available on most of the satellites and many others.
But we are not there yet.
Many of the issues that we are facing on Earth, or we have faced on Earth maybe 20-30 years ago, is actually still dominant with respect to space technologies. We see a lot of challenges with respect to just even being able to communicate with your infrastructure, unless you are using, for example, solutions like Starlink, which is still not widely adopted beyond being siloed with other SpaceX solutions.
And this is also proven by recent research which has shown that around 50% of satellite traffic is still unencrypted, especially if you consider that in the past, only state-level actors were actually able to go into orbit and listen to their traffic.
Nowadays, launching things into orbit is becoming commoditized. If you just buy any type of cheap software-defined radio, anyone can listen to traffic that is being sent and broadcasted to Earth.
With this shift in mind, we built our architectures accordingly. Over the past, roughly 18 months, when we started to build SpaceComputer, there are actually many fundamental challenges we had to solve before we can actually reach the reality of large-scale systems that can run in space.
SpaceComputer's Security Services
SpaceComputer aims to provide a security layer where we have our own constellation of satellites to be equipped with unique type of capabilities, that can integrate with other third-party constellations. And users on Earth will be able to access our services but we also envision in the future that other satellites themselves will be able to use our capabilities.
Our services are unique in their security capabilities, but it's also a pain from engineering perspective. We design with respect to physical isolation, because once we send stuff, it's hard to maintain it, but also it provides superior security guarantees. The infrastructure operates beyond borders, beyond reach, and it's immune to physical tampering once it's up in space.
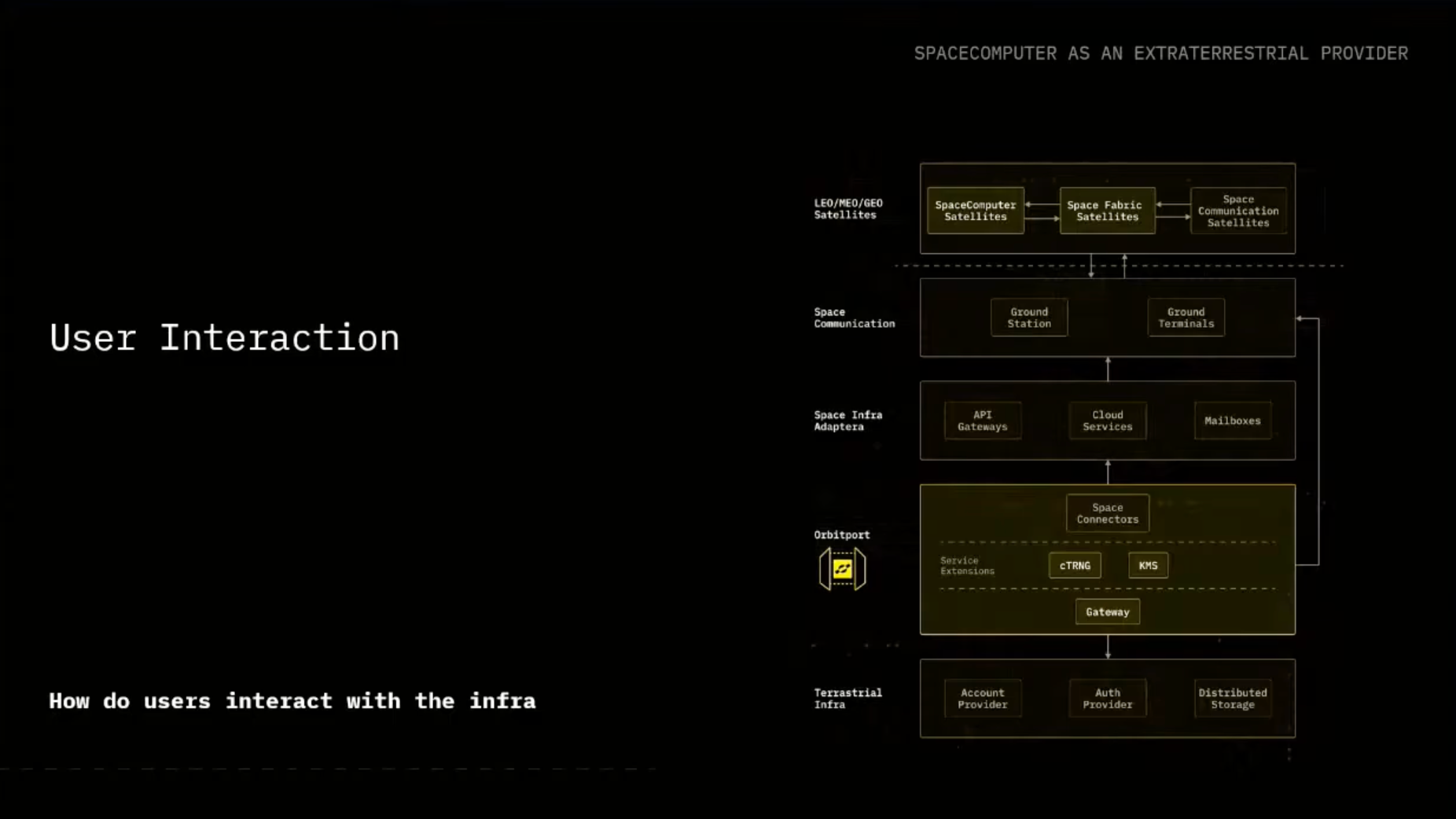
Our Solution: Orbitport and Seamless Experience
We believe users on Earth should have a seamless experience, as they are used to when interacting with AWS or other solutions.
While unable to offer this seamless swap at this time, it's the goal we are chasing as a company to provide as a solution. We are designing our secure gateway called Orbitport that aims to provide the interface between the users on Earth, offer the services to them, and also provide the abstraction to the users so they can easily communicate with what is happening in space, either with other satellites, with our own satellites, or, as we will introduce later on, space fabric-equipped satellites. And Orbitport itself will be managing the interface between different level of ground station providers.
As of now, if you want to talk with some of your infrastructure in space, you really have to rely on sending your messages to a ground station provider via email that will eventually forward it to space. And depending on the ground station provider, some are a bit more sophisticated with an API, some are not there yet.
This is one of the pain points we want to solve with Orbitport.
We want to unify the interfaces that will be facing to the ground station providers, and you as a user can just interact with an API that you are comfortable with, and can later on ensure that you will be able to communicate with your infrastructure in space. Kind of unlocking each of the individual items in the figure.
What does it mean to run something on our satellites, or what is actually SpaceFabric itself?
Maybe quick raise of hands, who of you have heard of Trusted Execution Environments (TEEs)? Wow, we have a TEE crowd here, which is great!
What are TEEs? SpaceComputer's SpaceTEE.
In general, TEEs are an isolated region on a CPU that is providing additional instructions to your application that you can later execute and run, and it promises secure location for your code and data.
Depending on the type of a TEE, it aims to offer confidentiality and integrity for the data that are running inside of the enclave. Its most crucial aspect is providing a remote attestation capabilities, so you can actually verify to others with a cryptographic proof that your application is actually running inside of a Trusted Execution Environment (TEE) itself.
For those that already know, there are in general two types of TEE families: process-based TEEs and VM-based TEEs.
- For process-based solutions, we in general see that we are just able to run a particular sensitive compute as a part of the process inside of the enclave.
- For VM-based solutions, we are actually putting the whole confidential compute environment into a virtual machine (VM) that is something that you can easily run.
The main difference is the size of the Trusted Compute Base (TCB).
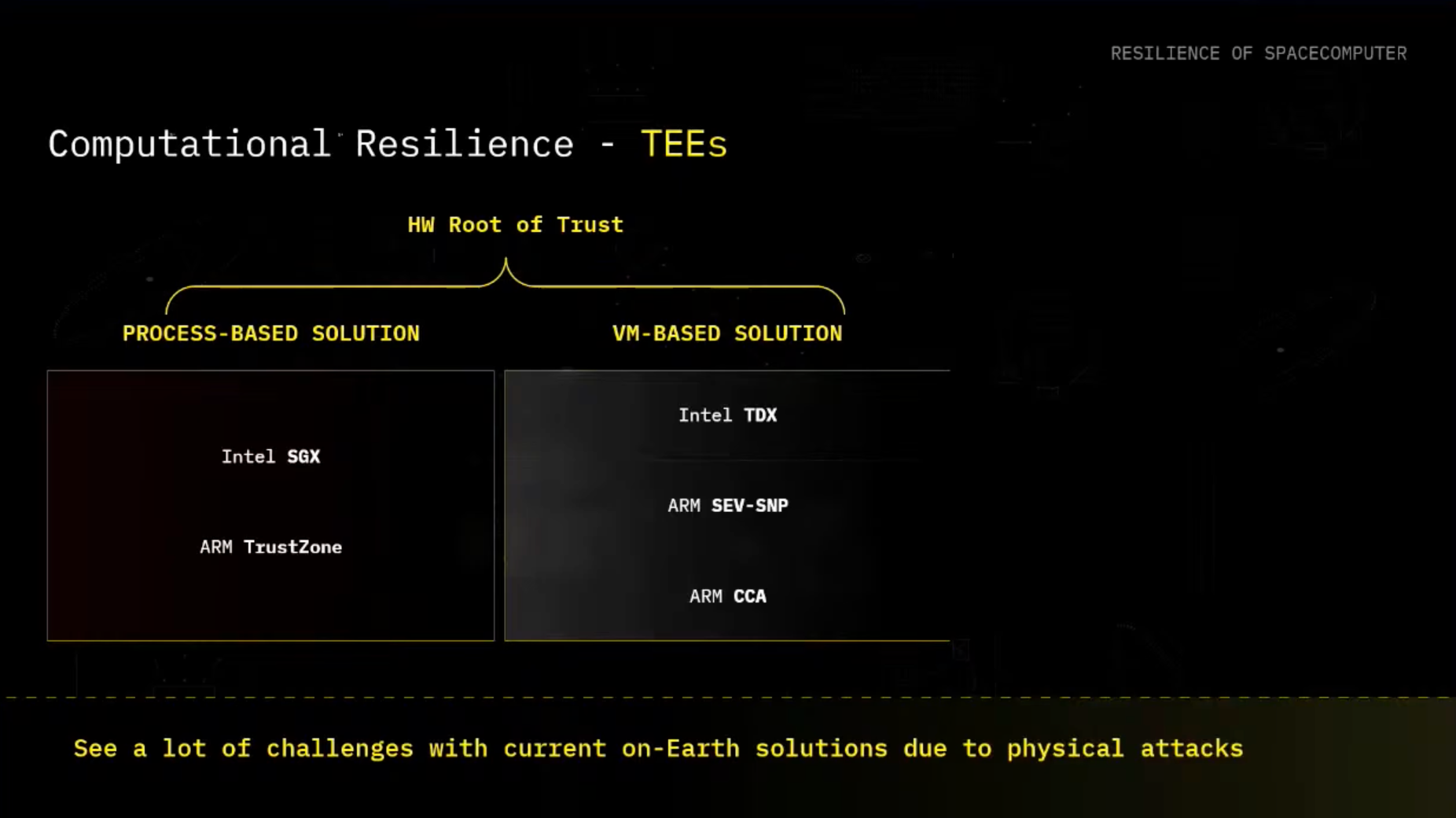
Going a bit deeper on VM-based TEE solutions: If you have the whole virtual machine that's assumed to be trusted running inside of the TEE, it's a bit larger in comparison to the process-based solutions. Also the threat model is slightly different in the context that here you assume malicious hypervisor, and actually for the process-based, you can assume malicious host operating system as well.
In recent months and years, we have seen quite a few issues with the TEEs, especially due to the threat model they have, which basically currently relies on a so-called 'guy with a Glock,' who is actually ensuring the physical protection of TEEs.
In the recent months, there has also been quite a few attacks exposing a trace of the sensitive key material out of the TEE, and even be able to create an attestation that your code is actually running in an authentic information.
Which inherently means that actually you have to trust the operator not to behave maliciously. Which of course is always sparking when there's a new issue with TEE, it's always sparking an interesting X worse with respect to posts that these are dead, and they don't have future. I think it's not about that, I think these definitely provide an interesting value, and I think it should be considered as one of the security solutions we have out there, in combination with cryptographic-based solution.
Solution to TEE security challenges: Space Fabric
And for that, we can introduce one of our solution actually aims to solve some of the issues we know with TEEs, and this is called Space Fabric. We just published it last week, and it generally tries to actually think of a future architecture for designing confidential computing in space. And it tries to address some of the challenges we see with TEEs on Earth.

And I will just provide some of the key contributions in here in high level, and kind of how do we position ourselves. So in the past, there was also the direction about just SpaceTEE, which was the idea of having a software that is just available on your particular machine with physical isolation. But what we start to see more and more, and this will be definitely a big topic in the space industry, is like you want to, not having a dedicated satellite for your particular mission, but you start to be interested in multi-tenancy.
What does it mean? That you are not necessarily in the mood to trusting the other people that are sharing the same infrastructure, and for that, we are designing Space Fabric that is providing quite an interesting set of capabilities. Some of the unique issues that are known in the TEE community is that, of course, I didn't dive into it in detail before, as a part of the TEE, the station flow, usually the manufacturer itself is injecting itself into the hardware root of trust. TEEs in general have the issue that they tell, actually, what is the code they are running, but they don't actually tell you anything about where is the code that is running.
Of course, the other aspect is auditability and supply chain, and lastly, especially I think with the announcement of Google, everyone is talking about it quite heavily, is the post-quantum cryptography transition. It's possible, just like it's something that has to be, I think, more actively discussed as well. And looking at it, we try to look for possible solutions to these problems.
So what we identify will be the suitable solution is:
- Make sure that the private keys that are used as a part of attestations are never generated on Earth.
- We rely on two secure elements for our attestation flow.
- One of them is open source completely, even the hardware design and the firmware is open source.
- The second one is established certified solution.
- And we have identified and designed our own instantiation of so-called proof of execution triangulation (ET).
In a short proof of ET, you can ask what came up first, if the ET or the actually words behind it. In this case, we are focusing on actually describing, which is the interesting property, is trying to find a way on how we can actually prove our execution is happening in space. And for that, we have instantiated our protocol that we call Satellite Execution Assurance Protocol (SEAP).
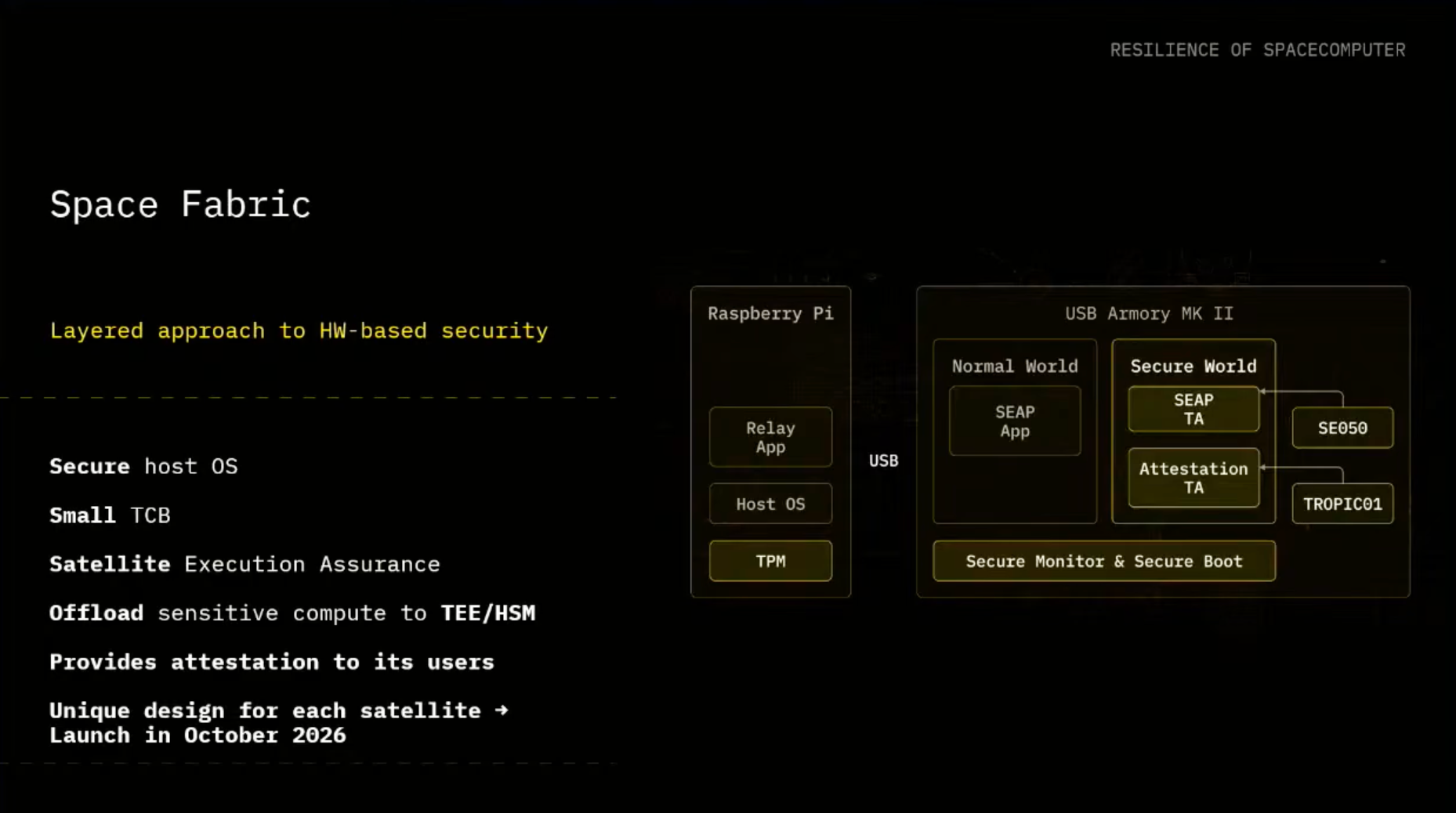
Our Proprietary Solution: The Satellite Execution Assurance Protocol (SEAP)
That actually is kinda using the ground stations to issue a form of like a challenge response protocol that will ensure that your satellite is actually really an authentic satellite and it's running in space. And we are in general providing and using the secure approach of making sure the host is secure. We are trying to minimize the trusted compute base (TCB).
We are finding the aspects of how to offload a sensitive compute to the TeE in combination with the Hardware Security Module (HSM) that are providing us the key material, and in general try to provide attestations to its user.
So we unfold all of these aspects in the paper, but the cool part from our side that satellites equipped with our solution will be available later on this year. We have three missions plans ahead of us, and the first one will be later on this year in October 2026. So if you're interested to find out more, you can check out the space for the paper.
Orbitport: The gateway for accessing space infrastructure
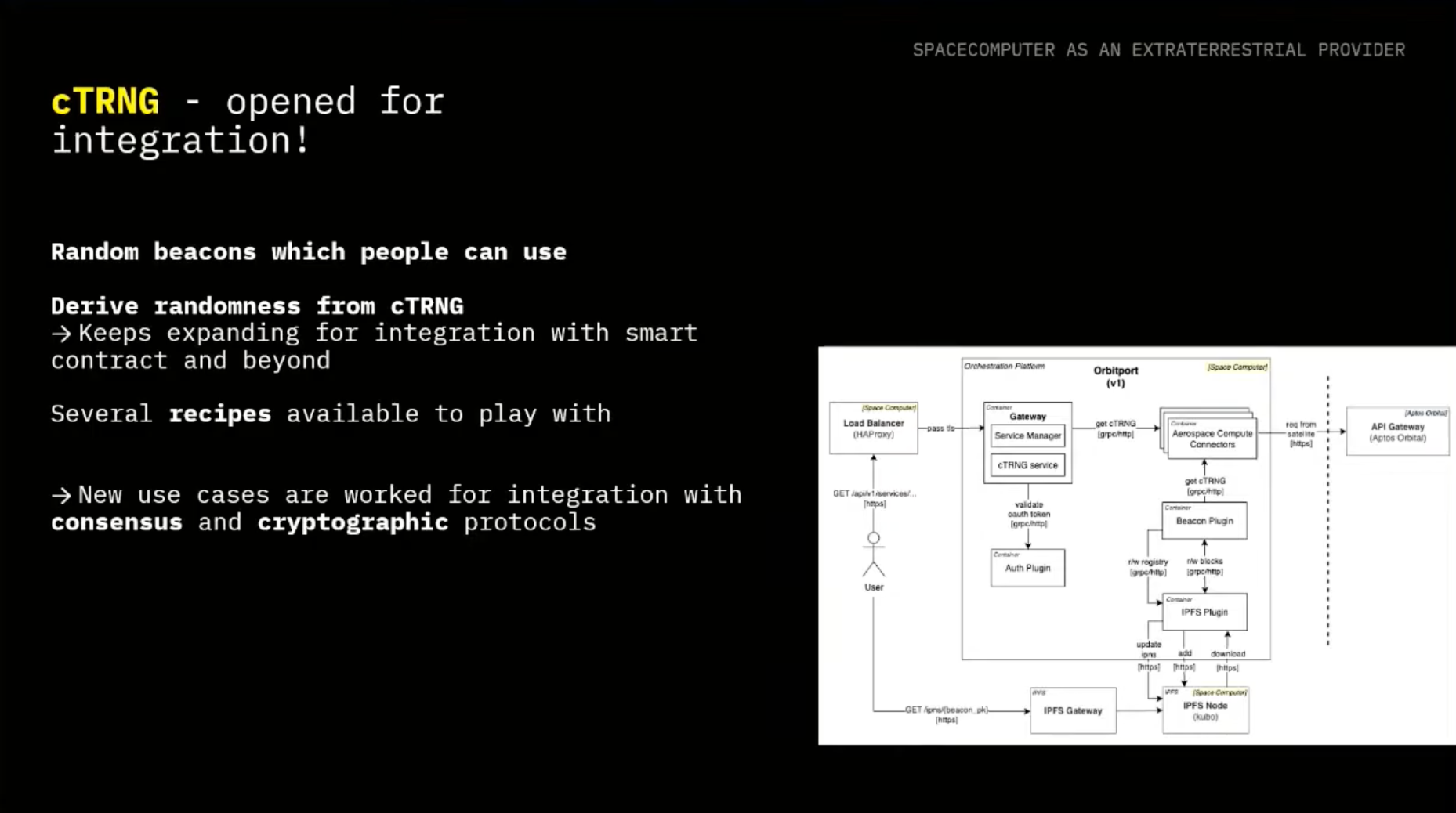
Now let's dive into actually how do we communicate with it, which is where Orbitport comes into the picture. It aims to provide to the users this trust-minimized gateway that is able to communicate. It's providing also the end-to-end confidentiality and integrity, and in general, aims to unlock several of our use cases. One of them will be cTRNG, as we'll be looking into more detail.
And as of now, we are the only party managing it, but we'll be partnering with several organizations to run our gateway on their infrastructure, inside of TEEs in orbit and on Earth. We want to unlock and make this gateway more trust-minimized. One of the solutions is to use TEEs on Earth as well, partner with other parties, and, in general, make it open source so actually other people can also go and deploy their instance of Orbitport.
In the future, we aim to make sure that anyone who wants to interact with Orbitport can run it on-prem or in different type of settings as well.
Unlocking unique applications in orbit
One of the features we can unlock from orbit randomness. It's one of the, I would say, funky for us because, of course, you always want to get some radiation from space.
And now is the question, how can you actually consume it? Toufic will be diving into the details, actually what are some of the tricks we do to make sure that the user is confident that our randomness is the relative random number that we are consuming. We already have a couple of recipes you can play with if you're interested. And in general, we are looking also into the aspects of not only public randomness that you can consume as you are used to for NFTs and others, but also find a way on how we can consume private randomness in consensus or other cryptographic protocols themselves.
And something that's very exciting for us is Key Management Service (KMS), which is a new offering. We are currently launching in phase zero for initial partnership integration. In general, as of now, we are building the solution custom to us because, of course, we have to build for space where we want to run eventually the whole KMS stack.
But for now, we are starting to build it on Earth with eventual transition in a hybrid setting between Earth and space, and eventually running it full in space, which will be unlocked by thresholdizing some of the components and using the TEEs along the way. So if you are interested, let us know. We also have a portal, basically, as people are used to.
If you want to register through OAuth, you can get your respective tokens, and you can start to play around with infrastructure.
And Toufic will now unlock more of the details regarding cTRNG. Thank you. Thanks, Filip, for giving an overview.
cTRNG: Cosmic True Random Number Generator and Randomness Beacons
So yeah, one of the applications that we have with our space infrastructure is cTRNG. And we were first thinking, why are we talking about randomness? Usually, when we're talking about cryptographic protocol security, we are talking about code, about audit, about monitoring, and we treat randomness as an assumption. But we should not.
So randomness is used in a lot of places, in decentralized applications, in web3 mechanisms, such as selection, ordering, or consensus, and also in core cryptographic protocols. If you have any key generation, signature, non-generation, you need strong randomness. And so the problem that we're trying to solve here is basically making sure that we're having true randomness.

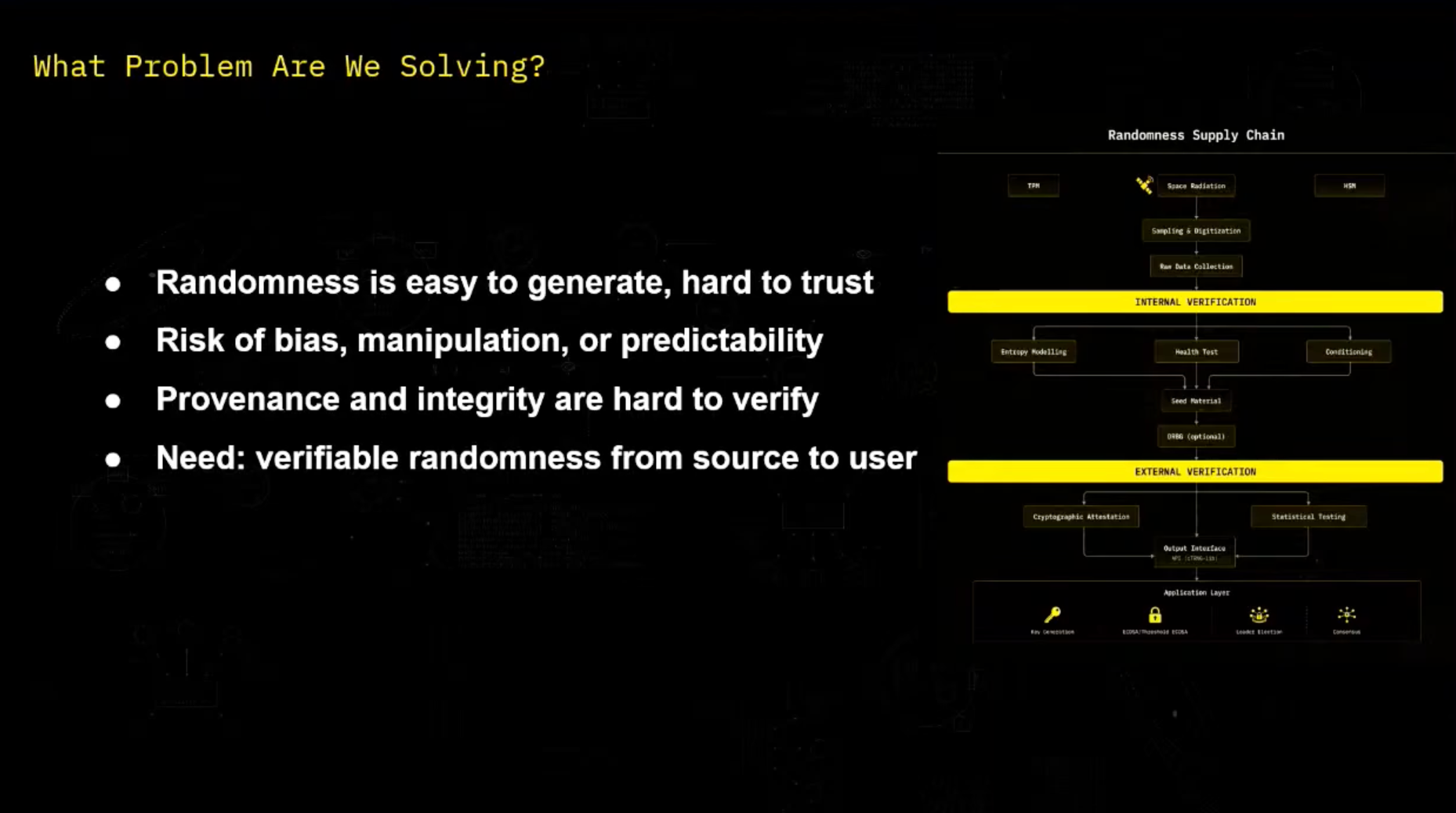
We want to make sure that we are generating randomness correctly, that nobody is able to guess it in case that we have real private randomness, that nobody also is able to bias it or influence the random numbers that we're going to get. And also, we need to make it verifiable by the user. And we can see that as a randomness supply chain, we're starting with randomness collection.
And at the end, we want to have randomness that is usable by the user in the application layer. And what we are going to see is all the steps in between, so that the user can be confident about it. What are the current existing solutions? For now, we have external solutions in which the user that uses the randomness does not generate it itself.
And we have, here again, different subcategories. We have a blockchain solution. So it's easy for the user to use it.
But he has to trust someone else to provide that randomness to it. We have also some on-chain solutions. It's transparent and easier to consume.
But it's harder to deliver, because there is not really native randomness on-chain. So you have to trust someone to provide that randomness to you. And how you trust that person, or how do we trust that group of person, and it's also harder to deliver.
So this is one group of solution. And the other way, you can just not trust anyone and generate your randomness locally, maybe on your computer or just by an external device. But it's a bit complicated to make it right.
And also, you are vulnerable to several kinds of attacks, like side-channel attacks. And your device can be compromised also. So we need a solution for all of this that keeps the source trusted to make sure that you know what's happening, how randomness is generated.
And that randomness should be preserved through transportation. And at the end, you should be able to verify what's happening. And that's the role of our CTRNG, which is Cosmic True Random Number Generation.
So we are taking randomness from space, space radiation, which is as much as we know for now a non-deterministic process. And using it as a source of randomness. And one of the main benefits of it is it's outside the reach of any other attacker.
So any side-channel attacks, any compromission is an old threat model. And now the question is, how can we be confident that randomness is correctly generated and transported? So Filip briefly talked about TEEs. And it's one part of the solution.
And now let's take a look at other parts of the solution. So when we want to verify that randomness is correctly generated, we have two parts of the story. The first part is internal view.
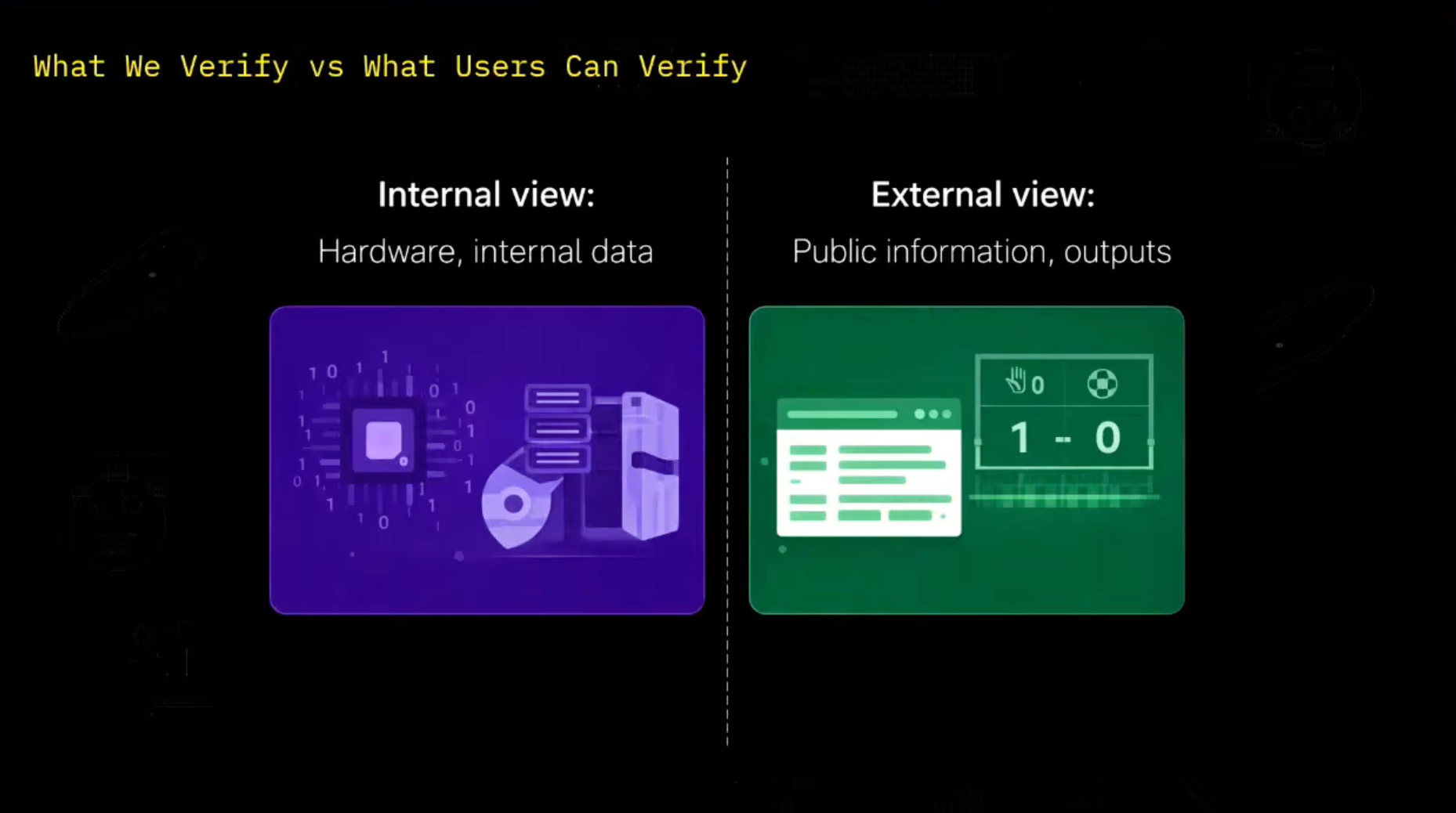
As a designer at Space Computer, we have access to data that public user does not have. We have access to the internal state. We have access to the data that is captured by the sensors.
And we have access to the whole system. And on the other hand, the user, he only has access to the public information. He has access to the documentation.
To open source code. To any attestations that we publish. And of course, he has access to the random number.
And it's two different versions that need to be separated separately. So yeah, before diving into the separation, let's just briefly take a look at the type of random number generator. So a TRNG is a true random number generator.
And it extracts randomness from a physical source. It's non-deterministic, which is what we want from a randomness source. But it has a lower throughput.
Because each time you want randomness, you have to query that source of randomness. And on the other hand, we have pRNG, which are pseudo-random number generators. And you give it a seed as an input.
And you just get as an output a sequence of random number. It's pseudo-random, so it's deterministic. And it's faster, but it's predictable.
So if an attacker gets access to the input seed, then he's able to recover the whole sequence of number. And so let's start here with internal verification, how first we make sure as designers to correctly generate that randomness. And for this, we use the NIST SP-190 series, which is a certification framework.

And it's divided in three parts. So NIST-A is about how to correctly design a deterministic random bit generator, which is the NIST equivalent of a secure pRNG. On our end, we're not reinventing anything.
We'll use existing one, like CHA-20. So I'm not diving into this. NIST-B is about the entropy source and the entropy estimation, how we make sure that the sensors in space are providing enough randomness.
And NIST-C is about combining NIST-A and NIST-B, the entropy source and the DRBG, to have a full usable RNG. So let's take a look at NIST-B and the analysis of the source of entropy. So we first here have the analog noise source, which is our raw space radiation in our end.
And we digitalize it, and we get some raw data. And this is first digital noise source. We can apply some conditioning on it.
I'll explain more later what the goal of this is. And then we need to apply some Hale-Stelz auto to make sure that it's working correctly. And all of this forms the entropy source.
And our goal is to ask, how random is our source? But what is it exactly? How random is the source? Let's try to define it. So imagine that I have a source of randomness. For example, I have a source that outputs number between 1 and 10.
And you here are an attacker and trying to guess what will be my next output. So if my source is fair, for example, each value is probable at 10%, whatever you will be guessing, you will have a success rate of 10%, which is as good as we want, as much as possible in that case. If our source is based, for example, 7 appear 50% of the time, if you choose 7, you will have a success rate of 50%.
And so you will have a higher rate of guessing. And we can assume that my source is less good than this one. And if my source is broken, then you choose 7, and you have 100% success rate.
And so we can try to think about randomness as the more success rate has an attacker on guessing my next number. But you could be telling me, for example, if my source is based and 2 appears 0% of the time, if you choose 2, you will have a 0% success rate. And we could conclude that this source is better than this one, even if it's based.

But our goal here is to take your best guess as an attacker, so that on our end, we have a lower bound on our entropy estimation, so that we know that we have at least that much entropy in it. And it's a conservative way of thinking about security. And this is just the formalization of this intuition.
So we define the entropy as the opposite of the logarithm of Pmax, where Pmax is the best guess of the attacker. And when we apply it to the result before, we just see that the lower is Pmax, we end up with a higher entropy. And the more our source is broken, the less entropy that we have, and it makes sense.
And so we know how to define entropy. And to define entropy, we need to calculate Pmax. But in practice, Pmax is not that easy to calculate, and we need to estimate it.
And for that, we have estimators, and we have a different way to calculate it. And it first depends on the model. If your variable is IID, identically distributed and independent, then you can just count the symbol frequencies, and then get an estimation of Pmax, depending on what is your frequency in your data set.
And if it's not an IID, you have a list that provides some other estimators. You have, for example, Markov chain or compression based estimator. And so the goal here is to take all that list of estimator.
You have around 10, and you take the minimum, and that's your lower bound. And to do this on the raw data calculation, you need to take around 1 million data point to collect them before any calculation. So also, you need to perform health tests.
You need to perform a health test at startup to make sure that each time that you're restarting your source, it started correctly. You need to have also test on demand to make sure that whenever you're having insensitive operation, you make sure and check that your source is working correctly. And you also need to have continuous testing to make sure that it's not sliding over time.
And for example, some tests, it includes like repetition count test. It detects a long growth of the identical value. If you have a lot of zeros, it should be warning up.
And the additive proportion test also, it checks how the frequency is evolving over time. If you used to have a certain frequency and now it's changing, you should have an alert. And then once you have your raw output, you may apply conditioning depending on what is your clarity on your output because you still can have some bias or correlation.
And for example, if you have an output of eight bits, maybe inside it, you only have four bits of entropy. And your goal is to compress it into a cleaner output so that now in four bits, you have four bits of entropy. And you need to understand that this conditioning, it does not create more entropy.
And you need to estimate the entropy before applying that conditioning. And then depending on which conditioning you use, if it's approved by NIST or not, then you're able to claim full entropy or not saying like, if I provide eight bits, 100% of that amount is full entropy. So yeah, now let's talk about NIST-C.
So NIST-C is about the construction of the full random bin generator. And so we've just seen how to estimate entropy on the entropy source. We've not seen, but we will be using a DRBG from NIST-A.
And NIST-C is about combining both. Like you have the entropy source and you give it as an input to the DRBG. And it explain how to seed and re-seed from the source.
When it explain also what is a bit limit, because you can't like use one seed and generate random numbers infinitely. It explain what bit limits you should use. And it also explain how to combine multiple sources if you have more than one.
And what we need to understand here is that this NIST certification is a baseline. We should not trade it as a proof that our source is secure, but it's something that considered good enough to be used in most cryptographic application. But we still have to keep up with research because we have a lot of new attacks and things that are discovered.
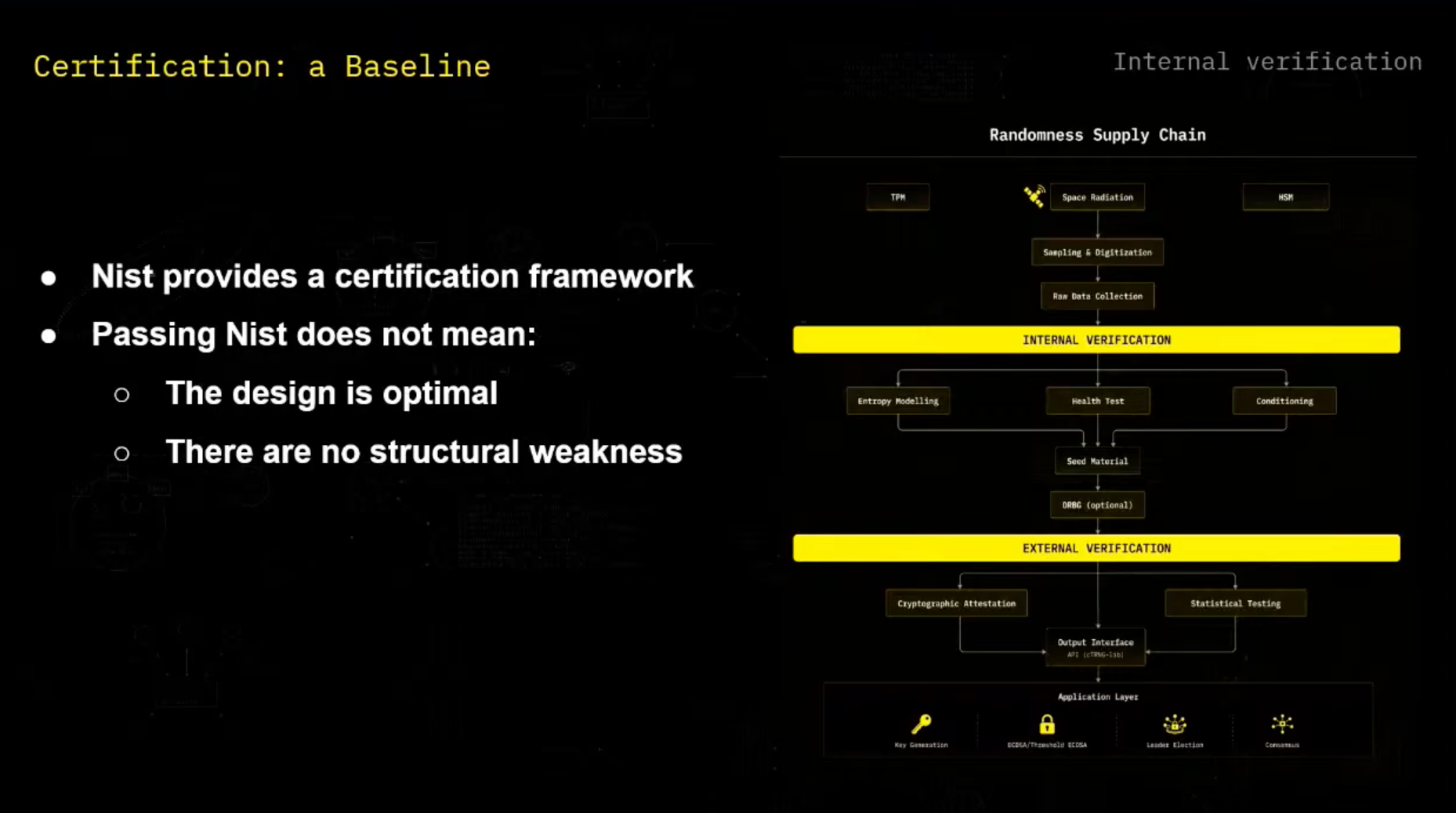
And so here with our randomness supply chain, so we have some randomness generation here. For example, yeah, space radiation that we discussed. We sample digitize it and then we have our raw data collection.
And then we can apply as internal verification as a team, as we discussed, which is entropy modeling, health test, and then conditioning. And then we will see how it can be usable to the external verification. And so yeah, for recall, external verification, it's for the user point of view.
So the user, it sees our product as a black box and he only has the public information that's available. And his goal is to check as much as possible if the received value looks correct. And we have two tools for this.
We have statistical verification that I'll explain and cryptographic mechanism that Filip talked about it briefly, but I'll re-go on it again. And so the statistical verification, the goal is that the user, he got some random numbers that we provided from space computer, and he want to take a look at this random number and say, does it look random? And the goal is to detect a bias or correlation, but it only try to look if it looks random. It cannot prove that it's random.
It's only trying to guess if there is things that are obviously broken, but that's the most that it can do. And in practice, we have some statistical test suite like DieHard or DieHarder or NIST, but the most recent one are TestUser1 and Procton, and we'll see how it works. So each test on TestUser1, it computes a statistic on the data and see how much is it surprising.
For example, let's say that we have a generator that outputs number between one and 10. And let's say we're drawing 1,000 number and our statistic will be counting how much seven do we have. We expect to have 107, but we can do more than this.
We can say that we have less than 1% chance than of filing outside the 75, 125 range, and we have around 10% chance of filing outside the 85, 115 range. And we can use this to say, for example, if we get like 500 as a count, it's suspicious. It's still possible.
If we get it one time, it can still be true. But if we have different tests and we have different very low probability, then we can suggest that our entropy source is broken. And so, yes, the p-value is what formalizes.
It's how surprising is the expected result under our hypothesis. And if the p-value is too small, we reject our hypothesis. And if it's not too small, then we can just say that we were not able to reject our hypothesis.
But we cannot prove anything here. Concerning statistical verification, we will soon release a library on it, which is a REST library, which includes two of the most recent tests, which is TestUser1 and Practrend. And we have two kind of bindings here, REST2C, in order to be able to call our REST code to the library and C2REST in order to be able to call back the results.
And, yeah, the goal is that this is open source and pluggable into whatever REST repository. So you're able to verify with this, our source of randomness. But whatever source of randomness in the crypto world, you can verify it with this statistical verification library.
And here, we just have an example of how it's working. So we took an example with the classic RNG, which is SHA-20. You define it.
You register it. And then, depending on which battery test you want to run, for example, if it's small verification you want to do or it's a big one, you run the corresponding test and you do your verification. And then, this was statistical verification.
And now, let's look at the other way of verifying things, which is cryptographic verification. And one of the first way we can verify things by having signatures on the output, if the data is signed, then I know that the data comes from the satellite. So I know where it's coming from, but I just know that it's coming from the satellite.
I don't know if it's what generated correctly. And that's the role of TEE attestations, is to make sure that I know that this number was generated on this satellite, and I know it was generated with this code and this process, and it's attested. And another thing is verifiable DRBG output.
We can imagine for public beacons that as a space computer, we can commit to a DRBG seed. And later, when we reveal that seed, the user can replay the sequence, verify it himself. And we have also some option to not only commit on the seed and use that seed as the input of the DRBG, but commit on a seed and use the input as a hash of the seed and a public value, for example, a block hash, so that we know that we have not biased the output.
So yeah, it all depends on the use case. And here, yeah, we can retake a look at the randomness supply chain to situate things. So one of the things we've talked about is space radiation, but on space, we also have TPMs and HSMs that are true source of generation and that have a way to generate random number.
So space radiation is one of the source, but we have two others that are also NIST-approved. And so yeah, we've seen how we collect the data. We've seen how we do internal verification.
And now we have our input, our output. The user can verify it and first perform a cryptographic attestation verification, but also perform statistical testing on it. And now he has an input that he can use in whatever he wants, in key generation, in a threshold EDCDSA, in leader election.

And this is all like private beacon example, but we also can provide public beacon output to make sure that, for example, if we have a lottery or whatever public numbers that is needed, it can be used also. And so yeah, we're presenting now a Crypto-ctrng, which is our library that enables you as a user to access the random numbers that we are providing from space. And it's a REST library that transports that entropy from our backend to the user.
It implements the standard sets so that it's pluggable and it can be replaced in any RNG. It has three entropy sources. The first one is IPFS beacon, which is a 32 byte blocks that comes from the cTRNG backend.
This is our main source. Another one is local OS. If you don't trust the randomness for space, or if you want maximum security, you can use your local one in order to get it mixed so that you have the randomness from space, your local randomness and your XOR both.
You have three modes then. You have raw entropy if you just want the entropy and then plug it into your custom cryptography mechanism. And if you want to have our DRBG on top of it, which is a CHAT20 construction, you can use our and then you can apply auto-receive on top of it, which is like every 3,200 bytes or every week, whichever comes first.
And if you want maximum security, you can use a prediction resistant mode in which you're calling our API at every call in order to receive your RNG. So let's take a look at an example of integration into an existing cryptographic protocol. So for recall, what is threshold ECGSA? Instead of having one user that have a secret key and that generates a signature, we're splitting that private key into different shares.

And then each user has a share that he used to generate a partial signature. And we can combine this partial signature to get the final signature. So it's a way to split the private key to have some more security.
And we could say that it already provides enough security. If each user is generating randomness on its own, maybe I'm able to guess one part randomness, but it will be very hard to guess the other. But that's when we see that we have some setups in which it's difficult.
For example, when we have some virtual machine and some configuration, if they have some same setup configuration, we can end up by being able to gather randomness from all the VM concurrently. So here we're having the code of the Loch Ness repository from DFNS in which they perform threshold ECGSA. So first we define our EPFS random source with a beacon key.
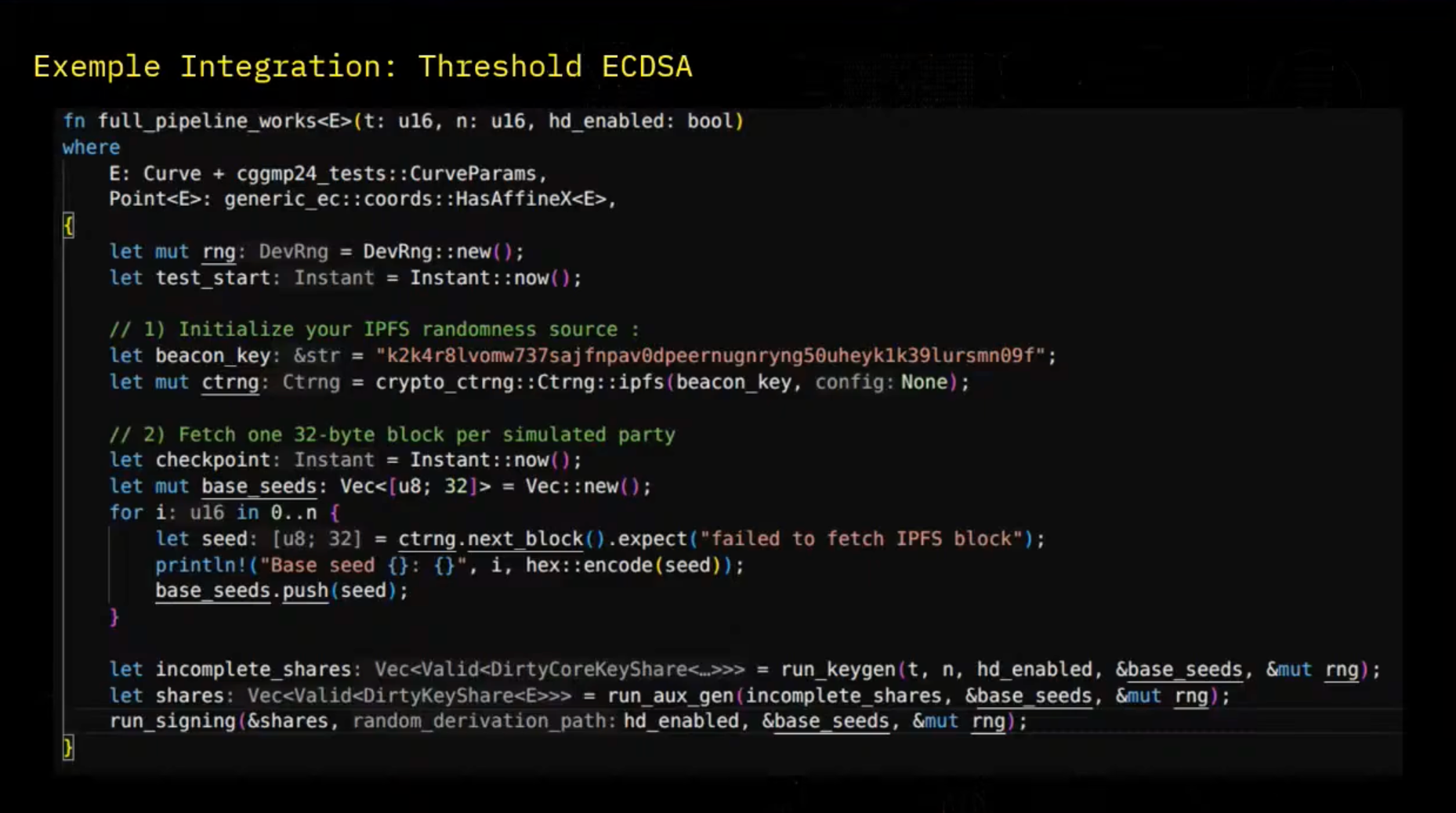
And there we're able to call it like this with the cTRNG.ipfs and we give our beacon key as an input. And once we've defined our cTRNG, we are simply able to call it with cTRNG.nextblock. And so for each user, each party in the protocol, he's calling a block in the cTRNG protocol and we're having a base seed. And then this base seed can be used in different parts of the protocol, in the key gen, in auxiliary data generation, which is the key generation and splitting part.
And then we can run signing. And so here in this specific repository, they do not use our specific DRBG. So we tried to adapt to their implementation.
They're using their seed and then they are deriving it for each stage. For example, here it's key generation. So it's stage one.
And so for each stage, they derive their seed in order to get local randomness that is different for each round without having to re-trigger different randomness generation. And yeah, so we derive randomness and then we can run the key gen. And yes, that was the big picture.
So thanks for being here listening. And if you have any need for randomness integration or anything else, let me know. Great, we are happy to take any questions from the audience or we will be also here later on.
Audience Questions
Question 1
"Very technical deep dive, so thanks for that. I have a bit of a general question. So there's been a destruction of a couple of SpaceX satellites in the last two days. I think two went down. Is there any data redundancies that you're thinking? Like if there's anything in space and you cannot service that and it goes offline, like you probably cannot store data for long periods of time there. So how did you deal with that?"
It's a great question. So we are actually on that part already thinking of the designs with respect to that. This is, and it's kind of a layered approach.
So one part, of course, if it's a single satellite that we'll be initially having, it's of course hard to have too much redundancy on that front of if something goes wrong with the particular spacecraft, it's a problem. But already on this particular spacecraft, we actually are adding multiple redundancies. So we, for example, have more of the same boards on board of the particular satellite as well.
So in case one of the boards is, for example, damaged due to radiation or over the extended period of time of just being in a bit more of a hostile environment in space, we can switch to the other board. And also on the particular board, we actually have two instances of the TEEs. So that way we can actually handle the particular sensitive compute in two different modes.
And with respect to the data itself, we are, since most of the sensitive operation will be running inside of the TEE, we are actually also encrypting them with respective key. And we are later on storing the copies of the encrypted data in different locations on the satellite as well. So that way, even if there is a issue with a particular storage, for example, the SD card, we have a way on how to deal with it.
And moving forward, we, of course, want to also have a redundancy across multiple satellites. That is also the motivation why we don't want to have only a single satellite, but a constellation, because you can later on distribute and synchronize the state across multiple PRSN satellites in space, because what you are mentioning is possible. It can happen.
And in general, also, there will be a churn in the network. Like some satellites will disappear. Some satellites will join.
So you basically have to always make sure that there is enough redundancy across the different peers. One of the solutions Toufic was talking about is, of course, to use oscillators on a cryptographic level to protect the private cases, to federalize them, and have them stored at multiple locations. And think about it in a structured manner.
We're actually currently working on a more detailed blog post on outlining our strategy, which is like a mix of hardware and software solutions to make sure that, for example, we are on a regular basis also doing health checks, because even if the data are stored, it doesn't mean that they are healthy. They can, for example, be a bit flip on the radiation front. So you want to also have regular checkups and basically all of the health of the files is still up there.
Right. Can I actually add to this? You said there's a bit flip with potential radiation. And I assume that with, like, solar flares, and it might happen more frequent than you might expect.
So, like, what kind of, like, health checks would you perform? And how do you verify that the data is still, like, the randomness is random. It's not, like, becoming unrandom in that sense. Actually, this will maybe be helpful for us.
But, for example, for private keys, it can be a problem. So we want to be either doing checksums of the private keys if we happen to have access to them. This is one part.
And if, for example, if they are generated and stored inside of the HSM, we can, of course, do a checksum on the private key because we never get to see it. But what we can do is to just make it sign a dummy data and verify it against the respective public key, basically. And if there will be some issue that we will observe, we will have to regenerate the whole private key and the successive keys afterwards.
So we will have to basically do, again, like, a layered approach to solve this issue. But on a positive note, our satellites will be running on LEO. And actually, if you do quite a reasonable effort of putting some shielding onto the payload, you don't really have to worry about radiation as much, at least when talking with partners and discussing what is the likelihood of single radiation even happening.
For example, the BitFlip. During the experience of their spacecrafts, it never basically happened in the past. So in LEO, actually, you are quite safe because you are still quite close to the Earth and it's not such a big problem.
But of course, what is a general problem is that your hardware will be decaying a bit faster in comparison to on-Earth solutions as well, yeah.
Question 2
"Hey, thanks for the talk. I have a question because I don't know anything about space computing. How are you going to deal with the outdated computers? For example, you send a computer today. In 10 years, the compute power that it has is not state-of-the-art anymore, and I don't wanna use it. So how are you going to sort them off?"
It's a feature and a bug of space in some way, but basically, they will burn. So they will eventually burn on re-entry to the atmosphere. So, which is, I think, quite, we are using it currently more as a feature because if you have sensitive key material that is used in space and burns on re-entry, it's quite hard to actually go and try to get a private keys once the spacecraft is there. But definitely, it's something that we have to think about, but at least as of now, especially if you're launching satellites into space, you also have to have so-called sustainability plan, which basically is kind of telling you what is going to happen with your satellites at the end of the life.
For LEO, it's rather straightforward. They will actually just burn. For GEO satellites, it's quite funny, but they basically don't want to use enough propellant to be sending the satellite back to Earth and burning in the atmosphere.
They just push it farther from the Earth, and they're just stuck there. So actually, if you look at some of the pictures, you basically have a graveyard of old satellites that are beyond the geostationary environment. So they're still there from 70s, 80s.
They're just like chilling there. So for us, we want to rather burn them in the atmosphere because we're focusing on LEO, yeah. Okay, then if there are no further questions, well, feel free to reach out afterwards, and hope to see you around!

Head deeper into SpaceComputer's orbit:
→ Follow us on X (Twitter) and LinkedIn
→ Visit our website and learn more about the company and mission.
Contact us at services@spacecomputer.io if you're interested in SpaceComputer integrations, or via this contact form for general inquiries.
See you in Space!


