

Verifying True Randomness in Cryptographic Systems

Randomness is a foundational primitive in cryptographic protocols. It underpins security properties such as unpredictability, fairness, privacy, and resistance to adversarial manipulation. Key generation, nonces, salts, signatures, leader election, lotteries, and many consensus mechanisms all rely on randomness behaving as assumed. When randomness is weak, biased, predictable, or manipulable, entire protocols can fail.
These failures motivate a closer look at how randomness is generated. In practice, systems rely on different sources and constructions with very different security guarantees. PseudoRandom Number Generators (PRNGs) are deterministic algorithms that expand a short seed into long sequences that appear random but are fully predictable if the seed is known. True Random Number Generators (TRNGs) extract entropy from physical processes, such as CPU noise, space radiation, and other sources, providing non-deterministic outputs but often at the cost of lower throughput, greater complexity, and more difficult verification. Cryptographically Secure PseudoRandom Number Generators (CSPRNGs) aim to combine strong entropy sources with robust algorithms to ensure unpredictability even in adversarial environments. When evaluating TRNGs, an important aspect is that the randomness-generating process is sound.

At SpaceComputer, we provide a cosmic True Random Number Generator (cTRNG) based on physical measurements collected by sensors deployed in space. By observing space radiation, a fundamentally unpredictable physical phenomenon, we extract entropy that is independent of local software, hardware, or operating system assumptions on Earth.
This approach aims to mitigate common weaknesses of conventional randomness sources, such as environmental bias, insufficient entropy at startup, or partial adversarial control over local systems. The resulting randomness can be used directly as a high-quality entropy source, or combined with cryptographic post-processing to produce cryptographically secure randomness suitable for demanding cryptographic protocols.
However, claiming high-quality or “true” randomness is not sufficient on its own. Users and protocol designers cannot directly observe the physical entropy source in space; they only interact with its outputs and the information published alongside them. This creates a fundamental verification problem: how can one gain confidence that the randomness is genuinely unpredictable, correctly generated, and not degraded, biased, or manipulated at any stage of the pipeline? Addressing this requires a clear separation between what can be verified by external observers, and what must be validated internally by the system designers. For that, we consider two types of verification: first, the randomness's quality, and second, binding the randomness to its origin (space!) for accountability, using attestations.
First, external verification: what you can realistically check from public outputs and metadata. This includes statistical testing of outputs, as well as cryptographic mechanisms such as attestations and verifiable CSPRNG generation, which let you audit the process, not just the bitstream.
Second, internal verification: what we, as designers, must validate to justify strong claims about entropy and security. This is where entropy source validation comes in, and where standards like NIST SP 800-90B give a useful framework: raw data collection, IID vs non-IID modelling, min-entropy estimation, health tests, and conditioning.
The idea is simple: external checks help detect obvious failures and provide accountability, but they do not replace internal validation. Internal validation makes the claims real, external verification makes them auditable.
This can be viewed as a randomness supply chain, where different stages have different trust and accountability requirements: from physical entropy generation, through processing and transport, to consumption by cryptographic protocols.
Preliminaries
How do we verify that what we produce is actually correct to use for cryptography, both from our point of view as system designers, and from the user's point of view?
There are two very different perspectives here.
On one side, we have the internal view. As designers, we can see the full pipeline: the physical noise source, the sampling and digitization chain, the firmware and software, and the operational parameters. We can collect raw datasets, reproduce edge conditions, and run validation procedures that are simply not available to external users.
On the other side, external users mostly see what is public: documentation, any proofs or attestations we publish, and the random values they receive through the API. They cannot “open the box”, and they should not be asked to trust internal claims blindly.
1) External verification
There are two families of tools in external verification: statistical verification and cryptographic verification.
A) Statistical verification
Statistical verification asks a single thing: does this output behave like independent and identically distributed (i.i.d.) uniform randomness under standard tests?
It is a sanity check, not a proof of security. A generator can pass a lot of tests and still be predictable to an attacker who knows or can influence its internal state.
In practice you run established batteries like TestU01 and PractRand. The workflow is straightforward: collect a large stream, run the battery, inspect the results and failure patterns.
Under the null hypothesis “outputs are i.i.d. uniform,” each test computes a statistic and reports how extreme your observation is, as a p-value. The p-value is the probability of observing data at least as extreme as what you saw, assuming the null hypothesis is true.
What matters is not one p-value. With enough tests you will always see something slightly odd. What matters is repetition: the same tests failing across multiple runs, failures that only appear at scale, or failures that show up only in specific projections (low bits vs high bits, bit-reversed variants, byte order). Such structured patterns provide stronger evidence for rejecting the null hypothesis that the outputs are independent and identically distributed uniform variables.
What it cannot tell you is just as important. From outputs alone, you cannot quantify the entropy of the physical source, you cannot rule out operator influence, and you cannot detect side channels. Statistical verification can detect when something is wrong. It cannot prove that everything is secure.
B) Cryptographic verification
Cryptographic verification is not about “looking random.” It is about the integrity of the randomness supply chain: can the user verify that the output is tied to a specific, auditable procedure?
One approach is attestation. The service signs metadata and, depending on the setup, can provide remote attestation that binds outputs to a specific implementation, configuration, and device state. This does not prove unpredictability, but it makes operational claims checkable rather than trust-based.
Another approach is verifiable deterministic generation, typically with commit and replay. The provider commits to a seed first, then produces outputs from a CSPRNG, and reveals the seed later so anyone can replay the CSPRNG and verify the sequence was fixed in advance. If needed, the effective seed can be derived as H(seed || public_value), where public_value is something the provider cannot control, like a block hash at a predetermined time. This reduces the risk of adaptive manipulation in public randomness scenarios.
External verification can give you confidence that nothing is obviously broken, and that the generation process is accountable. Statistical tests help detect failures and regressions. Cryptographic mechanisms help users verify that outputs are bound to a stable implementation and a fixed procedure.
What it cannot give you is a defensible entropy claim. If you want to argue “this source provides at least X bits of entropy per sample under these conditions,” that is internal verification, and it requires access to the source, raw data collection, modelling, and validation. That is what we cover next.
2) Internal verification
Internal verification is what the system designers do to justify a concrete claim about their entropy source: how much unpredictability it provides, under which conditions, and what happens when it degrades. From a supply-chain perspective, this corresponds to validating the upstream part of the randomness supply chain, where entropy is physically generated, sampled, and conditioned, before any outputs are exposed to users.
A good reference for this work is NIST SP 800-90B. NIST is the U.S. National Institute of Standards and Technology, and the 800-90 documents are widely used as a baseline in security products. SP 800-90B is specifically about entropy sources: how to evaluate them, how to estimate entropy, and what monitoring is expected in a deployed system.
You can think of internal verification as validating the upstream randomness pipeline (the generation side of the supply chain) rather than a single output stream:
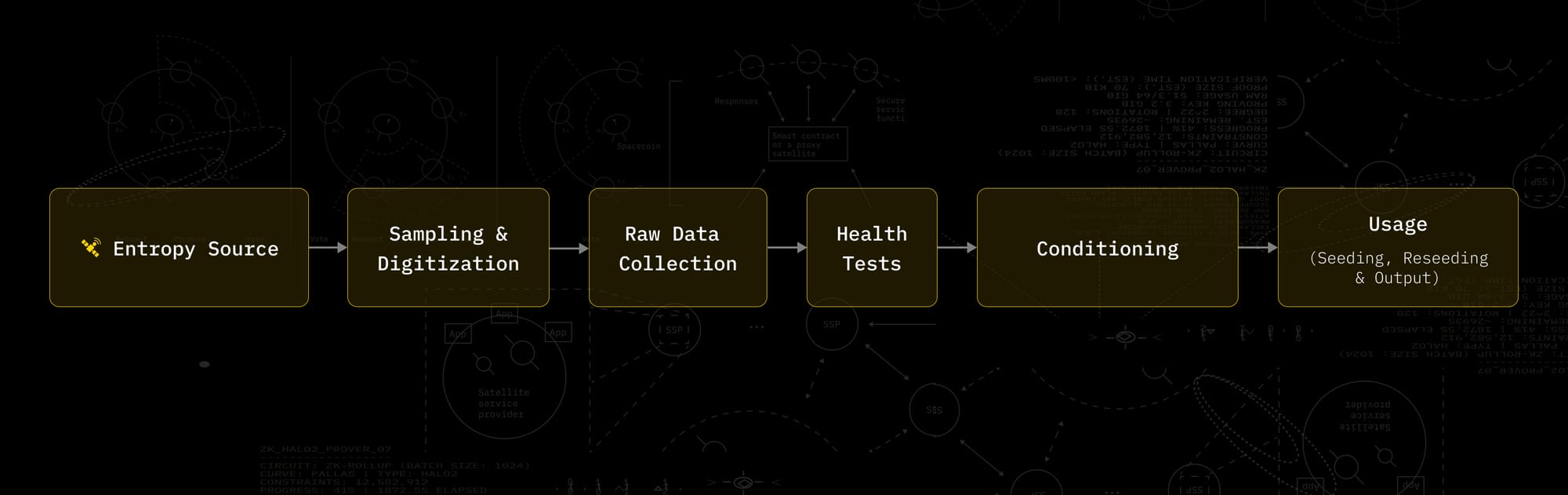
The point is not “these bits look random.” The point is we understand and control where the unpredictability comes from.
a) Sampling & Digitization
Sampling and digitization define how the physical entropy source is converted into digital samples. The sampling rate determines when and how often the source is observed, while digitization specifies how continuous measurements are mapped to discrete values.
These choices directly impact entropy and independence. Oversampling can introduce correlations, while insufficient resolution or poor quantization can reduce effective entropy. All later steps, raw data collection, entropy modelling, health tests, and conditioning, rely on the assumptions introduced here. For this reason, the sampling and digitization scheme must be explicitly defined and stable under the expected operating conditions.
b) Raw data collection.
The first step is to collect raw data from the entropy source, before any post-processing. This is the dataset you use to evaluate the source. Internal verification is stronger when raw data is collected across the operating conditions you actually expect in production.
c) Entropy estimation: quantify unpredictability
Entropy estimation requires choosing an explicit model for the source. SP 800-90B asks you to be explicit about whether the source can be treated as IID (independent and identically distributed) or not.
IID is the simplest case: samples behave like independent draws from a stable distribution.
Non-IID is the most common case, because of drift, correlations, and slow changes over time. SP 800-90B provides methods for both cases, but the non-IID track is more conservative.
Given this model, unpredictability can be quantified, typically using min-entropy. The outcome of this step is a lower bound on “entropy per sample” under stated assumptions.
This is different from statistical test suites on final outputs. Output tests are useful diagnostics, but entropy estimation is where you make the core claim: how much uncertainty an attacker faces, in the worst case.
d) Health tests: keep the source in the validated regime
Even a good entropy source can fail. That is why SP 800-90B includes health testing requirements.
Health tests run at startup and continuously while the system operates. They are designed to catch basic failure modes, like a source getting stuck or drifting away from its expected behaviour. When health tests trigger, the system should treat that as “stop trusting this source” and react accordingly (discard outputs, reseed, or enter an error state depending on the design).
e) Conditioning: making raw noise usable
Raw noise is often biased or messy. Conditioning is the step that turns raw samples into a cleaner stream suitable for seeding an RNG or being consumed directly.
Conditioning helps, but it does not create entropy. That is why internal verification estimates entropy at the source and then explains how conditioning is applied on top of that.
What internal verification produces:
At the end of the internal process, you want a simple set of deliverables:
- A defensible lower bound on entropy per sample, under stated assumptions and conditions
- A monitoring strategy (health tests) to detect when those assumptions stop holding
- A clear description of how raw data is conditioned and then used (seeding, reseeding, output)
With that in place, external users can still run their own checks, but your security claims no longer rely on trust or “it passed some tests”. They rely on a validation method that is designed specifically for entropy sources. However, NIST should be treated as a baseline, and complemented with current research and real-world incident learnings, because many RNG failures come from operational and implementation details rather than the high-level design.
External verification helps users detect obvious failures and audit how outputs were produced. Internal verification, following a framework like NIST SP 800-90B, is what supports real entropy and security claims: measure the source, state the assumptions, monitor it in production, and document how the bits are conditioned and used.
SpaceComputer Solution
SpaceComputer generates randomness in space by running TEEs on low Earth orbit satellite hardware that measures space radiation to extract entropy. Orbitport acts as the gateway that transports this randomness from the orbital environment to users and applications on Earth.
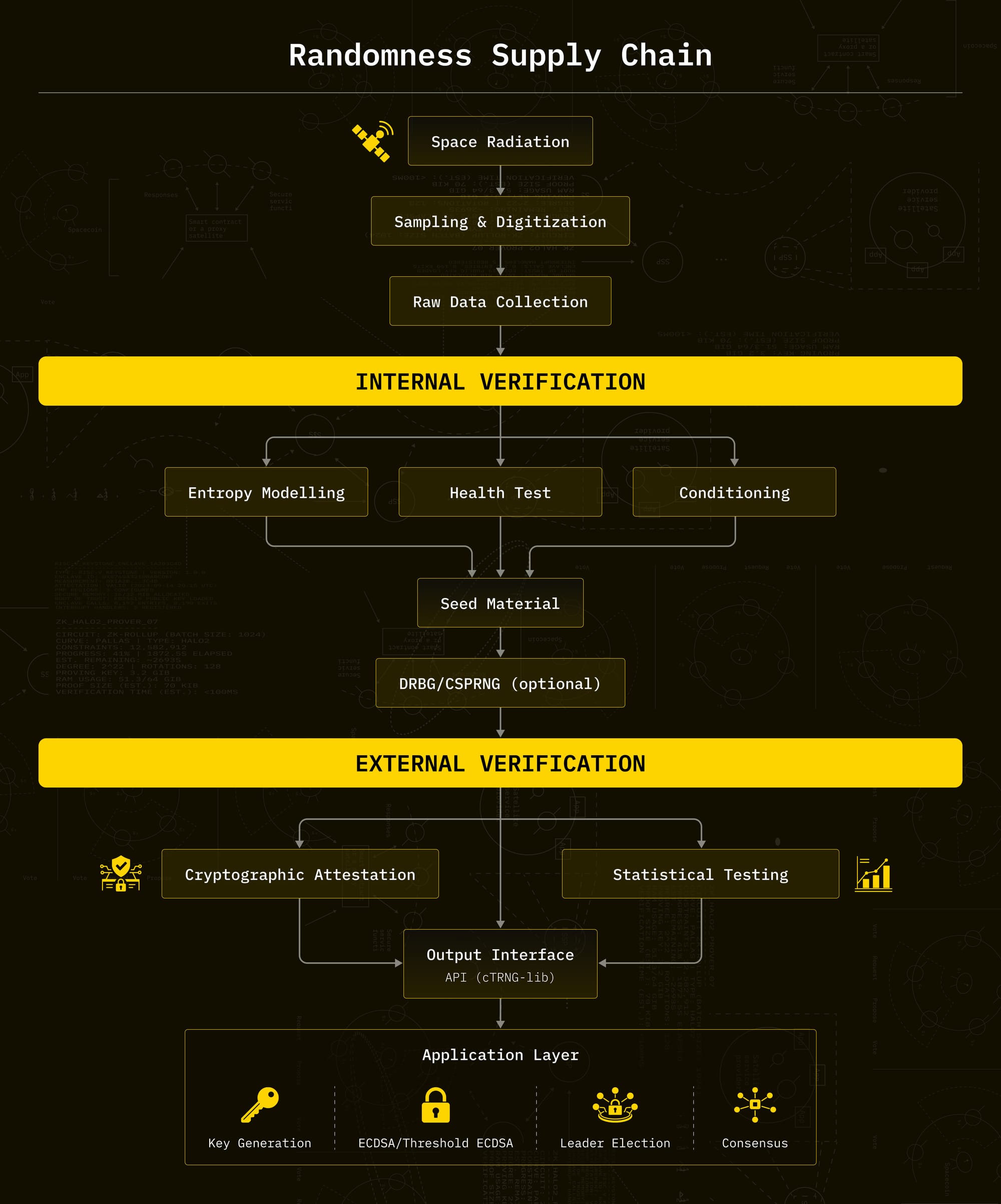
To ensure trust, each stage of the randomness supply chain is verifiable. Cryptographic attestations provide provenance, allowing users to verify where the randomness was generated, how it was handled, and that it remained secure and unaltered from space to Earth. In addition, our library provides statistical verification methods that users can apply to the outputs themselves. Together, this provides both supply-chain-level accountability (attestations) and output-level validation (statistical verification).
Application of our findings
We provide cTRNG-lib, a library that exposes this space-deployed true random number generator through a clean, developer-friendly API. From the user’s point of view, cTRNG-lib offers two main paths: request raw true random bits directly, or use those bits to seed a CSPRNG.
We use cTRNG-lib in threshold signature systems, where randomness quality directly impacts private key security and protocol robustness. In ECDSA, the signature nonce is a single point of catastrophic failure: if it is reused, biased, or even partially predictable, the private key can be recovered. Even in threshold ECDSA, there is still some risk.
More to come. Please subscribe for the following article!
Join the public Telegram chat for developer support.
Docs: docs.spacecomputer.io
Demo Videos: youtube.com/@SpaceComputerIO
X: @SpaceComputerIO